
| CV |
Email |
Github |
|
I am an incoming Ph.D. student at MMLab, The Chinese University of Hong Kong, advised by Prof. Hongsheng Li. Currently, I am pursuing my master’s degree in the School of Informatics at Xiamen University, advised by Prof. Xinghao Ding. I have research experience with leading research groups across academia and industry, including VITA-Group@UT Austin and InternRobotics@Shanghai AI Lab. My long-term research goal is to develop embodied foundation models with multimodal spatial intelligence, enabling agents to build scalable world models of the dynamic physical world and act reliably within it.
My current research primarily focuses on:
|
|
Project |
Abstract
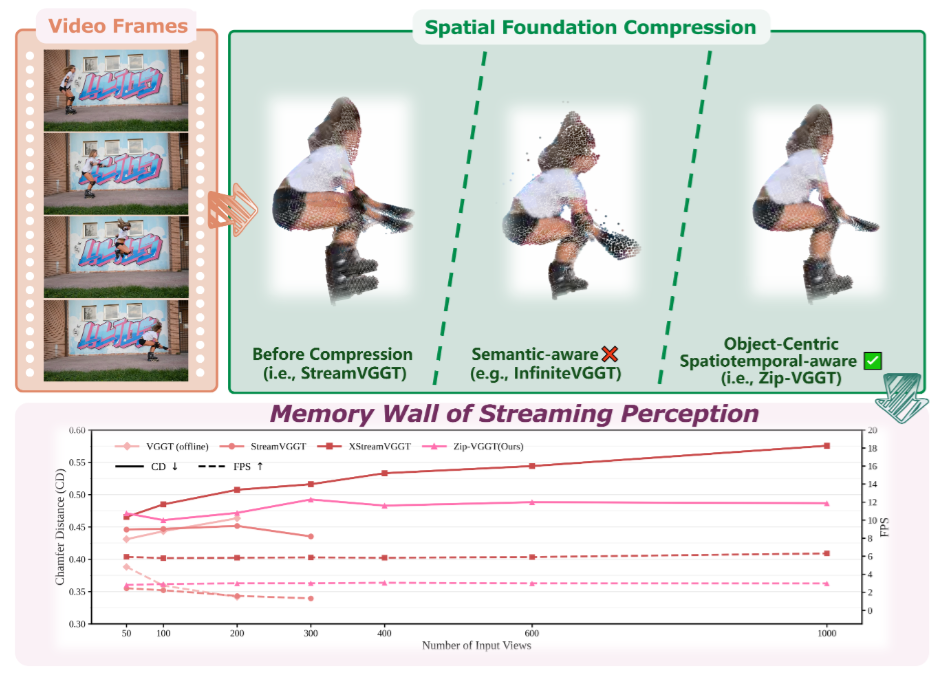
Streaming vision architectures have emerged as a powerful paradigm for embodied 4D spatial perception, enabling on-the-fly scene reconstruction. However, deploying these models in real-world infinite-horizon scenarios exposes a critical memory bottleneck: the unbounded accumulation of historical representations in the Key-Value (KV) cache. Existing token compression strategies attempt to mitigate this but suffer from decoupled, heuristic processing. They blindly aggregate tokens across physical boundaries, destroying high-frequency 3D geometry, and employ motion-blind eviction policies that erase the temporal trajectories of highly dynamic objects.
@misc{wen2025dynamicverse,
title={DynamicVerse: A Physically-Aware Multimodal Framework for 4D World Modeling},
author={Kairun Wen and Yuzhi Huang and Runyu Chen and Hui Zheng and Yunlong Lin and Panwang Pan and Chenxin Li and Wenyan Cong and Jian Zhang and Junbin Lu and Chenguo Lin and Dilin Wang and Zhicheng Yan and Hongyu Xu and Justin Theiss and Yue Huang and Xinghao Ding and Rakesh Ranjan and Zhiwen Fan},
year={2025},
eprint={2512.03000},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.03000},
}
|
|
Project |
Paper |
Abstract |
Bibtex |
HF Data |
Code
Humans inhabit a physical 4D world where geometric structure and semantic content evolve over time, constituting a dynamic 4D reality (spatial with temporal dimension). While current Multimodal Large Language Models(MLLMs) excel in static visual understanding, can they also be adept at “thinking in dynamics”, i.e., perceive, track and reason about spatio-temporal dynamics in evolving scenes?
@misc{wen2025dynamicverse,
title={DynamicVerse: A Physically-Aware Multimodal Framework for 4D World Modeling},
author={Kairun Wen and Yuzhi Huang and Runyu Chen and Hui Zheng and Yunlong Lin and Panwang Pan and Chenxin Li and Wenyan Cong and Jian Zhang and Junbin Lu and Chenguo Lin and Dilin Wang and Zhicheng Yan and Hongyu Xu and Justin Theiss and Yue Huang and Xinghao Ding and Rakesh Ranjan and Zhiwen Fan},
year={2025},
eprint={2512.03000},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.03000},
}
|
|
Project |
Paper |
Abstract |
Bibtex |
Video |
HF Data |
Code
Understanding the dynamic physical world, characterized by its evolving 3D structure, real-world motion, and semantic content with textual descriptions, is crucial for human-agent interaction and enables embodied agents to perceive and act within real environments with human-like capabilities. However, existing datasets are often derived from limited simulators or utilize traditional Structurefrom-Motion for up-to-scale annotation and offer limited descriptive captioning, which restricts the capacity of foundation models to accurately interpret real-world dynamics from monocular videos, commonly sourced from the internet.
@misc{wen2025dynamicverse,
title={DynamicVerse: A Physically-Aware Multimodal Framework for 4D World Modeling},
author={Kairun Wen and Yuzhi Huang and Runyu Chen and Hui Zheng and Yunlong Lin and Panwang Pan and Chenxin Li and Wenyan Cong and Jian Zhang and Junbin Lu and Chenguo Lin and Dilin Wang and Zhicheng Yan and Hongyu Xu and Justin Theiss and Yue Huang and Xinghao Ding and Rakesh Ranjan and Zhiwen Fan},
year={2025},
eprint={2512.03000},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.03000},
}
|
|
|
Project |
Paper |
Abstract |
Bibtex |
Video |
HF Demo |
Code [1600+⭐]
While neural 3D reconstruction has advanced substantially, it typically requires densely captured multi-view data with carefully initialized poses (e.g., using COLMAP). However, this requirement limits its broader applicability, as Structure-from-Motion (SfM) is often unreliable in sparse-view scenarios where feature matches are limited, resulting in cumulative errors.
@misc{fan2024instantsplat,
title={InstantSplat: Sparse-view Gaussian Splatting in Seconds},
author={Zhiwen Fan and Kairun Wen and Wenyan Cong and Kevin Wang and Jian Zhang and Xinghao Ding and Danfei Xu and Boris Ivanovic and Marco Pavone and Georgios Pavlakos and Zhangyang Wang and Yue Wang},
year={2024},
eprint={2403.20309},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
|
|
|
Project |
Paper |
Abstract |
Bibtex |
Code
Vision-centric perception systems struggle with unpredictable and coupled weather degradations in the wild. Current solutions are often limited, as they either depend on specific degradation priors or suffer from significant domain gaps. To enable robust and operation in real-world conditions, we propose JarvisIR, a VLM-powered agent that leverages the VLM as a controller to manage multiple expert restoration models. To further enhance system robustness, reduce hallucinations, and improve generalizability in real-world adverse weather, JarvisIR employs a novel two-stage framework consisting of supervised fine-tuning and human feedback alignment. Specifically, to address the lack of paired data in real-world scenarios, the human feedback alignment enables the VLM to be fine-tuned effectively on large-scale real-world data in an unsupervised manner. To support the training and evaluation of JarvisIR, we introduce CleanBench, a comprehensive dataset consisting of high-quality and large-scale instruction-responses pairs, including 150K synthetic entries and 80K real entries. Extensive experiments demonstrate that JarvisIR exhibits superior decision-making and restoration capabilities. Compared with existing methods, it achieves a 50% improvement in the average of all perception metrics on CleanBench-Real.
@inproceedings{jarvisir2025,
title={JarvisIR: Elevating Autonomous Driving Perception with Intelligent Image Restoration},
author={Lin, Yunlong and Lin, Zixu and Chen, Haoyu and Pan, Panwang and Li, Chenxin and Chen, Sixiang and Kairun, Wen and Jin, Yeying and Li, Wenbo and Ding, Xinghao},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}
|
|
|
Project |
Paper |
Abstract |
Bibtex |
Video |
Code [700+⭐]
Recent advancements in real-time neural rendering using point-based techniques have paved the way for the widespread adoption of 3D representations. However, foundational approaches like 3D Gaussian Splatting come with a substantial storage overhead caused by growing the Structure-from-Motion (SfM) points to millions, often demanding gigabyte-level disk space for a single unbounded scene, posing significant scalability challenges and hindering the splatting efficiency.
@misc{fan2023lightgaussian,
title={LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS},
author={Zhiwen Fan and Kevin Wang and Kairun Wen and Zehao Zhu and Dejia Xu and Zhangyang Wang},
year={2023},
eprint={2311.17245},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
|
|
|
Project |
Paper |
Abstract |
Bibtex |
Code |
HF Demo
Reconstructing and understanding 3D structures from a limited number of images is a classical problem in computer vision. Traditional approaches typically decompose this task into multiple subtasks, involving several stages of complex mappings between different data representations. For example, dense reconstruction using Structure-from-Motion (SfM) requires transforming images into key points, optimizing camera parameters, and estimating structures. Following this, accurate sparse reconstructions are necessary for further dense modeling, which is then input into task-specific neural networks. This multi-stage paradigm leads to significant processing times and engineering complexity.
@misc{fan2024largespatialmodelendtoend,
title={Large Spatial Model: End-to-end Unposed Images to Semantic 3D},
author={Zhiwen Fan and Jian Zhang and Wenyan Cong and Peihao Wang and Renjie Li and Kairun Wen and Shijie Zhou and Achuta Kadambi and Zhangyang Wang and Danfei Xu and Boris Ivanovic and Marco Pavone and Yue Wang},
year={2024},
eprint={2410.18956},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2410.18956},
}
|
|
National Scholarship (Top 0.2% Nationwide), 2022
National Scholarship (Top 0.2% Nationwide), 2020 |
|
International Conference on Machine Learning (ICML), 2025
International Conference on Learning Representations (ICLR), 2026, 2025 Conference on Neural Information Processing Systems (NeurIPS), 2025, 2024 SIGGRAPH Asia, 2026 AAAI Conference on Artificial Intelligence (AAAI), 2026 |
|
|